Что такое файл robots.txt и как его настроить
- Что такое robots.txt
- Директивы и структура robots.txt
- Как настроить robots.txt: советы
- Как проверить robots.txt онлайн
- Проверка в Яндекс.Вебмастер
- Проверка в Google Search Console
Читайте нашу статью, если хотите узнать, как сделать анализ robots txt. Мы расскажем, что это за файл и как его настроить, а также покажем, как делается проверка robots txt по правилам Яндекс и Google.
Что такое robots.txt
Файл robots.txt — это инструкция для поисковых роботов, в которой указано, какие разделы и страницы сайта они могут посещать, а какие должны пропускать.
Поисковые роботы — это программы, которые с определенной периодичностью просматривают содержимое сайтов и заносят информацию о них в базы поисковых систем (например, Яндекс и Google). Этот процесс называют индексацией сайта.
Если не настроить robots.txt, можно столкнуться, как минимум, с двумя проблемами:
- каждый раз сайт будет индексироваться очень долго (и, возможно, редко),
- роботы увидят нежелательное содержимое (например, служебные файлы или временную информацию) и страницы сайта будут “оценены” некорректно.
Всё это негативно скажется на позициях сайта в поисковой выдаче.
Если файл присутствует на сайте и настроен корректно, роботы будут действовать строго по указанным в нём правилам. Так они поймут, на какие страницы или разделы стоит обратить внимание в первую очередь, а какие скрыты от индексации.
Как правило, файл robots.txt создают и настраивают на сайте веб-разработчики. Но при должном желании это может сделать и любой владелец сайта. Для этого нужно знать структуру файла и его основные директивы.
Директивы и структура robots.txt
Как выглядит правильная структура файла, предлагаем рассмотреть на следующем простом примере:
User-agent: *
Disallow: /wp-admin
Disallow: /*?
Allow: /wp-admin/admin-ajax.php
Allow: /*.jpg
Sitemap: http://site.ru/sitemap.xml
А теперь объясним, за что в структуре отвечает каждая из директив:
- User-agent (для кого прописаны правила): помогает указать, что правила адресованы конкретным роботам (например, Yandex, Googlebot или другим) либо отметить (с помощью символа «*»), что они относятся к роботам из всех поисковых систем сразу;
- Disallow (запрет индексации): сообщает, какие разделы не должны обходить роботы. Эту директиву нужно прописывать обязательно, даже если на сайте нет служебных файлов (просто не указывайте значение). Без неё поисковые роботы не смогут корректно прочитать robots.txt.
- Allow (разрешение): сообщает, какие разделы или файлы роботы должны просканировать обязательно. Здесь стоит указывать только исключения из правила Disallow. Не нужно прописывать все разделы сайта — роботы автоматически обойдут все, что не запрещается правилами к обходу.
- Sitemap (карта сайта): должна содержать список всех страниц, доступных для индексации (следует указывать полную ссылку на файл в формате .xml.), а также время и частоту их обновления.
Как настроить robots.txt: советы
Чтобы поисковые роботы правильно выполняли указанные в файле условия, соблюдайте следующие основные правила:
1. Группируйте директивы. Если вы хотите указать разные правила для поисковых роботов каждой системы, создайте несколько групп с правилами и разделите их пустой строкой. Пример:
User-agent: Yandex # правила только для ПС Яндекс
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
# пустая строка
User-agent: Googlebot # правила только для ПС Google
Disallow: # раздел, файл или формат файлов
Allow: # раздел, файл или формат файлов
Sitemap: # адрес файла
Так роботы не будут путаться и им не придется искать нужную инструкцию во всём документе.
2. Учитывайте регистр. Для некоторых поисковых систем принципиально, чтобы название файла было указано только строчными или прописными. Например, Google правильно прочитает файл только в том случае, если вы укажите название файла строчными — robots.txt. Если этого не сделать, работы проиндексируют сайт некорректно.
3. Одна директива — один каталог. Для каждого раздела/файла нужно указывать отдельную директиву Disallow. Если вы напишите Disallow: /cgi-bin/ /authors/ /css/ — укажите три папки в одной строке — поисковые роботы не поймут, что им делать.
4. Удаляйте лишние директивы. После создания файла в нём будут директивы Host (зеркало сайта), Crawl-Delay (пауза между обращением поисковых роботов) и Clean-param (ограничение дублирующегося контента). Они считаются устаревшими, поэтому их лучше сразу удалить. Так роботам будет проще ориентироваться в правилах.
Как проверить robots.txt онлайн
Для этих целей существуют сервисы онлайн-проверки, например, Website Planet или PR.CY. Однако, если вы указывали правила специально для роботов Яндекс и Google, то проверять настройки нужно через их сервисы.
Обратите внимание: сервисы позволяют вносить правки в режиме онлайн — так вы сразу сможете понять, какие изменения помогут исправить ошибки. Однако эти изменения не вносятся в robots.txt автоматически. Код нужно поправить вручную (на хостинге или в административной панели CMS), а затем сохранить изменения.
Проверка в Яндекс.Вебмастер
Если раньше вы не пользовались сервисом Яндекс.Вебмастер, перед началом работы добавьте свой сайт и подтвердите права на него. Без этого у вас не будет доступа к инструментам анализа SEO-показателей и продвижения в поисковых системах Яндекс.
Чтобы проверить robots txt:
- Авторизуйтесь в личном кабинете Яндекс.Вебмастер.
- Перейдите в раздел Инструменты — Анализ robots.txt.
- Содержимое файла должно подтянуться в форму автоматически. Если этого не произошло, скопируйте код, вставьте его в поле и нажмите Проверить:
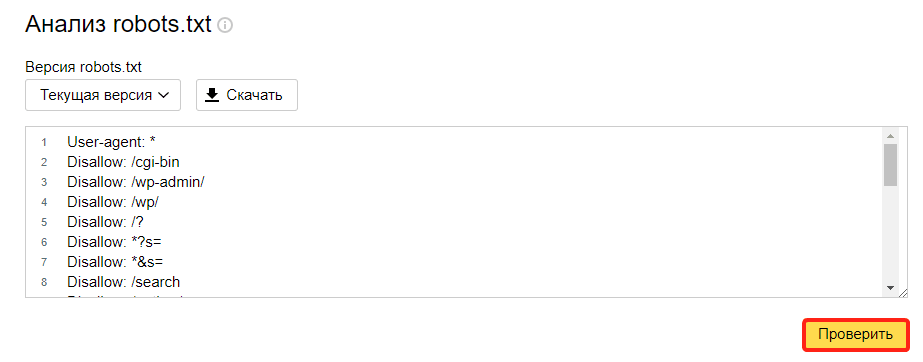
Готово, вы увидите результаты проверки. Если в директивах есть ошибки, сервис покажет, в какой строке, и опишет проблему: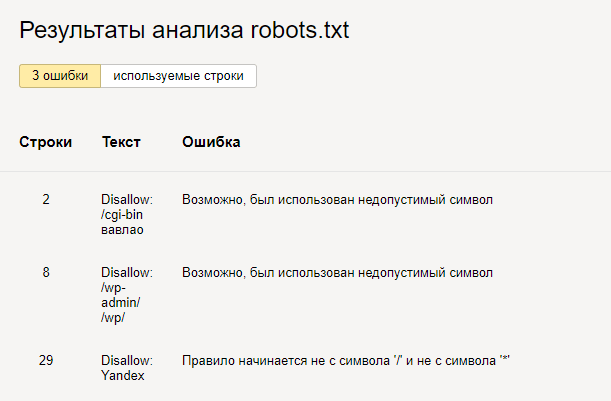
Проверка в Google Search Console
- Чтобы сделать анализ robots txt:
- Перейдите в сервис проверки.
- Если на открывшейся странице отображается неактуальная версия robots.txt, нажмите кнопку Отправить и действуйте по инструкции Google:
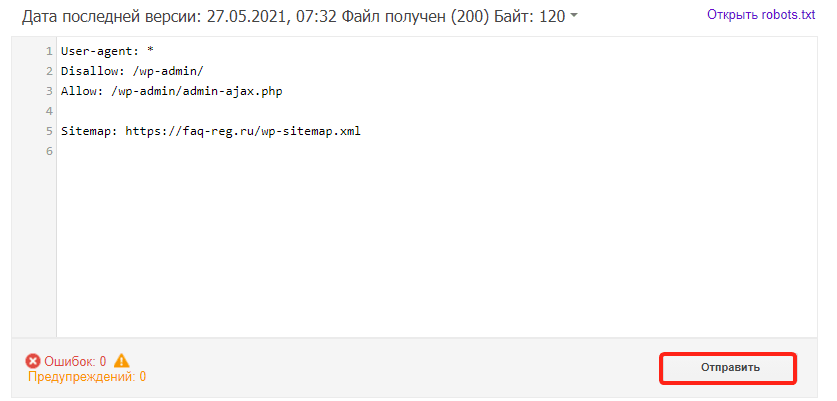
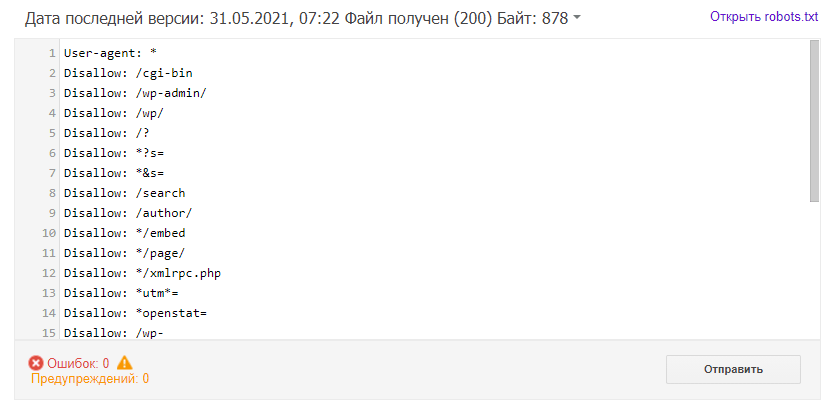
- Подождите несколько минут. Затем обновите страницу, чтобы увидеть актуальные директивы. Если система найдет ошибки, они будут перечислены под кодом.
Готово, в нашем примере проверка показала, что ошибок нет: